Skillnaden mellan UMA och NUMA

Innehåll

Multiprocessorer kan delas in i tre kategorier med delat minnesmodell: UMA (Uniform Memory Access), NUMA (Non-uniform Memory Access) och COMA (Cache-only Memory Access). Modellerna är differentierade baserat på hur minnes- och hårdvaruressurserna fördelas. I UMA-modellen delas det fysiska minnet jämnt mellan processorerna som också har lika latens för varje minnesord medan NUMA ger variabel åtkomsttid för processorerna för åtkomst till minnet.
Bandbredden som används i UMA till minnet är begränsad eftersom den använder en minnesstyrenhet. Det främsta motivet för tillkomsten av NUMA-maskiner är att förbättra den tillgängliga bandbredden till minnet genom att använda flera minneskontroller.
-
- Jämförelsediagram
- Definition
- Viktiga skillnader
- Slutsats
Jämförelsediagram
| Grund för jämförelse | UMA | NUMA |
|---|---|---|
| Grundläggande | Använder en enda minneskontroller | Flera minneskontroller |
| Typ av bussar som används | Enkel, multipel och tvärstång. | Träd och hierarkisk |
| Minne åtkomsttid | Lika | Förändras beroende på avståndet från mikroprocessorn. |
| Lämplig för | Allmänna applikationer och tidsdelningsapplikationer | Realtid och tidskritiska applikationer |
| Fart | långsam~~POS=TRUNC | Snabbare |
| Bandbredd | Begränsad | Mer än UMA. |
Definition av UMA
UMA (Uniform Memory Access) systemet är en delad minnesarkitektur för multiprocessorer. I denna modell används och åtkomst till ett enda minne av alla processorer som presenterar multiprocessorsystemet med hjälp av samtrafiknätverket. Varje processor har samma minne åtkomsttid (latens) och åtkomsthastighet. Den kan anställa endera en-, buss- eller tvärstångsbrytaren. Eftersom det ger balanserad delad minnesåtkomst, kallas det också SMP (symmetrisk multiprocessor) system.
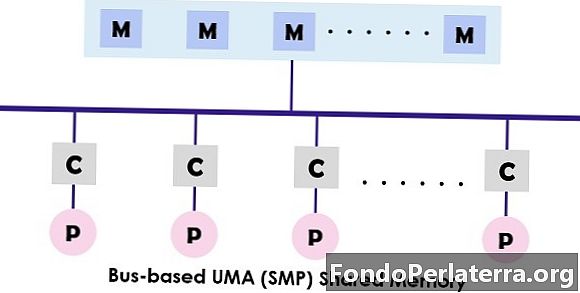
Den typiska utformningen av SMP visas ovan där varje processor först är ansluten till cachen och sedan kopplas cachen till bussen. Till sist är bussen ansluten till minnet. Denna UMA-arkitektur minskar striden för bussen genom att hämta instruktionerna direkt från den enskilda isolerade cachen. Det ger också en lika stor sannolikhet för att läsa och skriva till varje processor. De typiska exemplen på UMA-modellen är Sun Starfire-servrar, Compaq alpha-server och HP v-serien.
Definition av NUMA
NUMA (icke-enhetligt minneåtkomst) är också en multiprocessormodell där varje processor ansluts till det dedikerade minnet. Men dessa små delar av minnet kombineras för att skapa ett enda adressutrymme. Den huvudsakliga punkten att fundera över här är att till skillnad från UMA, förlitar sig åtkomsttid för minnet på avståndet där processorn är placerad vilket betyder att varierande minnet åtkomsttid. Det ger åtkomst till vilken minnesplats som helst genom att använda den fysiska adressen.
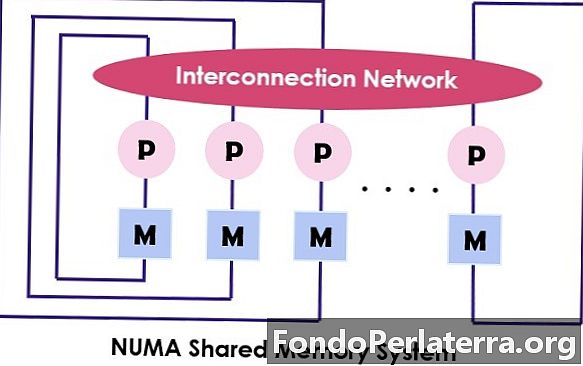
Som nämnts ovan är NUMA-arkitekturen avsedd att öka den tillgängliga bandbredden till minnet och för vilken den använder flera minneskontroller. Den kombinerar många maskinkärnor i "noder”Där varje kärna har en minneskontroller. För att komma åt det lokala minnet i en NUMA-maskin hämtar kärnan minnet som hanteras av minneskontrollern med sin nod. Samtidigt som åtkomst till fjärrminnet som hanteras av den andra minneskontrollern sänder kärnan minnesbegäran genom samtrafiklänkarna.
NUMA-arkitekturen använder träd- och hierarkiska bussnätverk för att sammankoppla minnesblocken och processorerna. BBN, TC-2000, SGI Origin 3000, Cray är några av exemplen på NUMA-arkitekturen.
- UMA-modellen (delat minne) använder en eller två minneskontroller. I motsats till detta kan NUMA ha flera minneskontroller för åtkomst till minnet.
- Enda, multipla och tvärgående bussar används i UMA-arkitektur. Omvänt använder NUMA hierarkiska och trädtyp bussar och nätverksanslutning.
- I UMA är åtkomsttiden för minnet för varje processor densamma medan i NUMA förändras minnesåtkomsttiden när avståndet från minnet från processorn ändras.
- Allmänna applikationer och tidsdelningsapplikationer är lämpliga för UMA-maskiner. Däremot är den lämpliga applikationen för NUMA i realtid och tidskritisk centrisk.
- UMA-baserade parallella system fungerar långsammare än NUMA-systemen.
- När det gäller bandbredd UMA, ha begränsad bandbredd. Tvärtom, NUMA har bandbredd mer än UMA.
Slutsats
UMA-arkitekturen ger samma totala latens för de processorer som har åtkomst till minnet. Detta är inte särskilt användbart när det lokala minnet nås eftersom latensen skulle vara enhetlig. Å andra sidan, i NUMA hade varje processor sitt dedikerade minne som eliminerar latensen när det lokala minnet nås. Latensen förändras när avståndet mellan processorn och minnet ändras (dvs icke-enhetlig). NUMA har dock förbättrat prestandan jämfört med UMA-arkitekturen.





