Skillnaden mellan personsökning och byte av operativsystem

Innehåll
Sökning och byte är två strategier för minnehantering. För utförande krävs att varje process placeras i huvudminnet. Byte och sökning båda placerar processen i huvudminnet för körning. byta kan läggas till vilken CPU-schemaläggningsalgoritm där processer byts från huvudminne till back-lagring och byttas tillbaka till huvudminne. personsökning gör att det fysiska adressutrymmet för en process kan vara icke-angränsande. Låt oss diskutera skillnaderna mellan sökning och byta med hjälp av jämförelsediagram som visas nedan.
- Jämförelsediagram
- Definition
- Viktiga skillnader
- Slutsats
Jämförelsediagram
| Grund för jämförelse | personsökning | byta |
|---|---|---|
| Grundläggande | Sökning tillåter minnesadressutrymmet för en process att vara otvetydig. | Byte gör att flera program kan köras parallellt i operativsystemet. |
| Flexibilitet | Sökning är mer flexibel eftersom endast sidor i en process flyttas. | Att byta är mindre flexibelt eftersom det rör sig hela processen fram och tillbaka mellan huvudminnet och butiken. |
| multiprogrammering | Sökning tillåter fler processer att ligga i huvudminnet | Jämfört med att byta växling tillåter mindre processer att ligga i huvudminnet. |
Definition av personsökning
Personsökning är ett minnehanteringsschema som tilldelar a icke-sammanhängande adressutrymme till en process. Nu, när en process fysiska adress kan vara osammanhängande problemet med yttre fragmentering skulle inte uppstå.
Sökning implementeras genom att bryta huvudminne i fast storlek block som kallas ramar. De logiskt minne för en process är uppdelad i samma fasta storlekar som kallas sidor. Sidstorlek och ramstorlek definieras av hårdvaran. Som vi vet ska processen placeras i huvudminnet för körning. Så, när en process ska genomföras, laddas sidorna i processen från källan, dvs back store i alla tillgängliga ramar i huvudminnet.
Låt oss nu diskutera hur sökning implementeras. CPU genererar den logiska adressen för en process som består av två delar som är Sidonummer och den sidförskjutning. Sidnumret används som index i sidtabell.

Varje operativsystem har sitt eget sätt att lagra sidtabellen. De flesta av operativsystemet har en separat sidtabell för varje process.
Definition av byte
För körning måste varje process placeras i huvudminnet. När vi behöver utföra en process, och huvudminnet är helt fullt, då minneschef swappar en process från huvudminnet till stödlager genom att evakuera platsen för de andra processerna att utföra. Minneshanteraren byter processerna så ofta att det alltid finns en process i huvudminnet redo för körning.
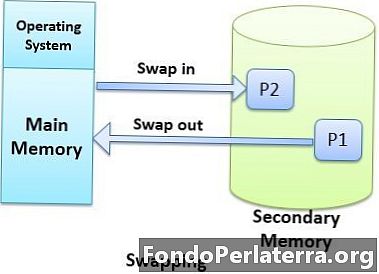
Även om prestandan påverkas av byte hjälper det att springa flera processer parallellt.
- Den grundläggande skillnaden mellan sökning och byte är att personsökning undviks yttre fragmentering genom att tillåta att det fysiska adressutrymmet för en process är otvetydigt medan, genom att byta tillåter för multi.
- Personsökning skulle överföra sidor i en process fram och tillbaka mellan huvudminnet, och sekundärminnet är följaktligen flexibel. Att byta byter emellertid hela processen fram och tillbaka mellan huvudminnet och sekundärt minne och följaktligen är bytet mindre flexibelt.
- Personsökning kan tillåta att fler processer finns i huvudminnet än bytet.
Slutsats:
Sökning undviker yttre fragmentering eftersom de inte sammanhängande adressutrymmena i huvudminnet används. Byte kan läggas till CPU-schemaläggningsalgoritmen där processen ofta måste in och ut ur huvudminnet.





